FAIDSet
FAIDSet is a multilingual, multi-domain dataset for fine-grained AI-generated text detection, comprising 83k+ examples across three authorship categories: human-written, LLM-generated, and human-LLM collaborative texts. It covers academic writing in English and Vietnamese, including paper abstracts and student theses, and spans multiple LLM families such as GPT, Gemini, Llama, and DeepSeek.
Designed to support robust and generalizable detection, FAIDSet captures diverse collaboration patterns and serves as both a training resource and a benchmark for evaluating performance under unseen domains and generators.
| Subset | Human | LLM | Human-LLM collab. |
|---|---|---|---|
| Train | 14,176 | 12,076 | 32,091 |
| Validation | 3,038 | 2,588 | 6,876 |
| Test | 3,038 | 2,588 | 6,879 |
| Total | 20,252 | 17,252 | 45,846 |
| Source | Human Texts |
|---|---|
| arXiv abstracts | 2,000 |
| VJOL abstracts | 2,195 |
| HUST theses (English) | 4,898 |
| HUST theses (Vietnamese) | 11,159 |
FAID
Training Architecture
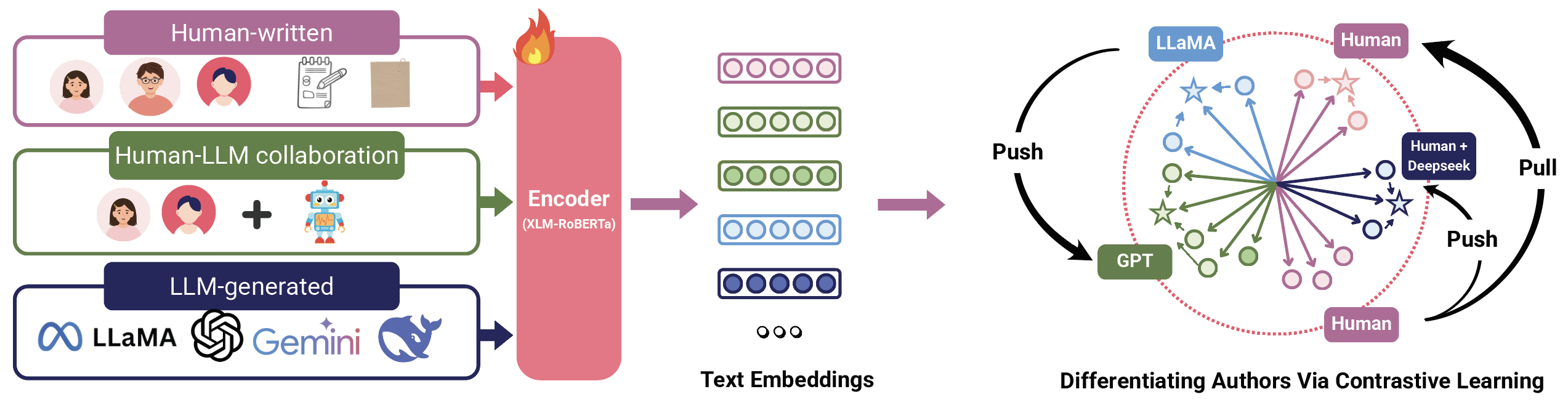
Leveraging multi-level contrastive learning loss, we fine-tune a language model (we select XLM-RoBERTa) based on the human, human-LLM and LLM-generated texts,to force the model to reorganize the hidden space, pulling the embeddings within the same author families closer, and pushing the embeddings from different authors farther. We train an encoder that can represent text with distinguishable signals to discern the authorship of text.
Inference Architecture
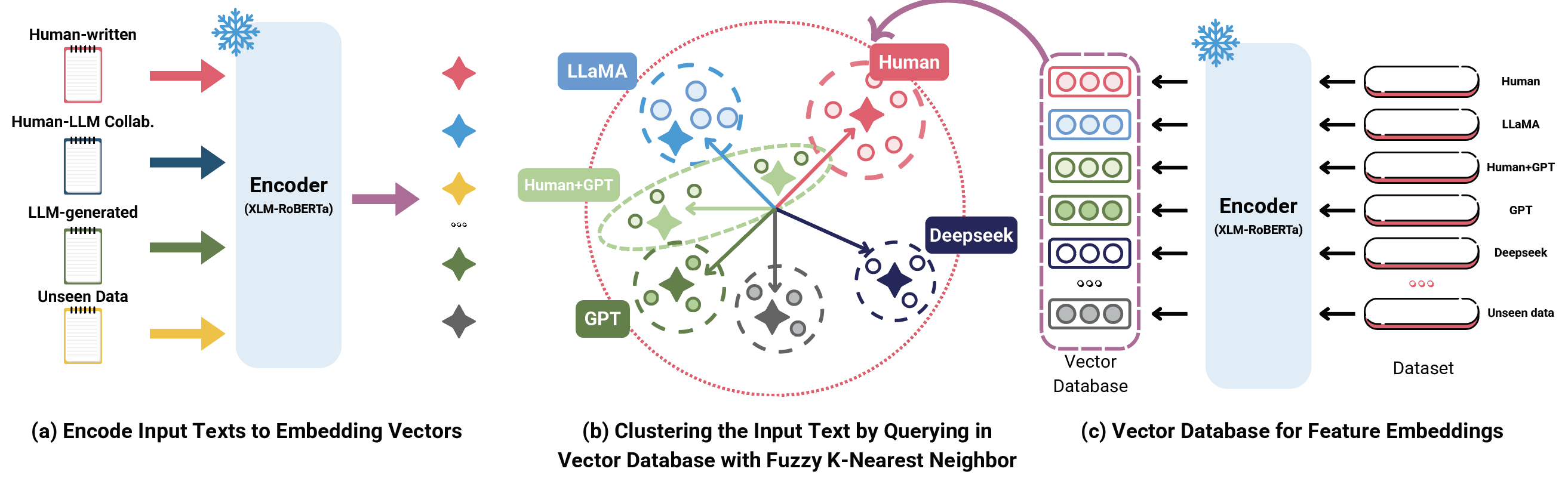
- Embed the input text into an embedding vector using the fine-tuned encoder.
- Use Fuzzy kNN to cluster the embedding, retrieving the cluster that the input text belongs to.
-
The stored vector database
VDis constructed by saving all embeddings of texts from the training and validation sets using the fine-tuned encoder. If the input text is unseen, it is embedded and stored in a temporary vector databaseVD', enhancing the detector’s generalization.
Main Results
Tables 1 and 2 summarize the three-label classification results (human-written vs. LLM-generated vs. human-LLM collaborative) for FAID and three baselines under both in-domain and out-of-domain settings. FAID consistently achieves the strongest performance, while SeqXGPT degrades notably on newer, more fluent generators.
Table 1: Performance on Known Domains and Generators
| Dataset | Detector | Accuracy ↑ | Precision ↑ | Recall ↑ | F1-macro ↑ | MSE ↓ | MAE ↓ |
|---|---|---|---|---|---|---|---|
| FAIDSet | LLM-DetectAIve | 94.34 | 94.45 | 93.79 | 94.10 | 0.1888 | 0.1107 |
| T5-Sentinel | 93.31 | 94.92 | 93.10 | 93.15 | 0.2104 | 0.1101 | |
| SeqXGPT | 85.77 | 85.49 | 86.02 | 84.69 | 0.5593 | 0.2844 | |
| FAID | 95.58 | 95.78 | 95.33 | 95.54 | 0.1719 | 0.0875 | |
| LLM-DetectAIve | LLM-DetectAIve | 95.71 | 95.78 | 95.72 | 95.71 | 0.1606 | 0.1314 |
| T5-Sentinel | 94.77 | 94.70 | 92.60 | 93.60 | 0.1663 | 0.1503 | |
| SeqXGPT | 81.48 | 78.72 | 74.91 | 76.71 | 0.3141 | 0.2255 | |
| FAID | 96.99 | 95.29 | 88.14 | 91.58 | 0.1561 | 0.0754 | |
| HART | LLM-DetectAIve | 94.39 | 94.25 | 94.33 | 94.29 | 0.3244 | 0.1789 |
| T5-Sentinel | 86.68 | 87.25 | 87.69 | 87.38 | 0.4339 | 0.2334 | |
| SeqXGPT | 63.12 | 64.01 | 65.27 | 64.05 | 1.0057 | 0.5982 | |
| FAID | 96.73 | 97.61 | 98.05 | 97.80 | 0.4631 | 0.1806 |
FAID consistently achieves the best overall accuracy and F1-macro across all in-domain benchmarks, including FAIDSet, LLM-DetectAIve, and HART. In comparison, LLM-DetectAIve and T5-Sentinel perform competitively but fall short of FAID, while SeqXGPT shows substantial degradation, particularly on datasets containing more advanced and human-like LLM outputs.
Table 2: Performance with Unseen Data
| Setting | Detector | Accuracy ↑ | Precision ↑ | Recall ↑ | F1-macro ↑ | MSE ↓ | MAE ↓ |
|---|---|---|---|---|---|---|---|
| Unseen domain | LLM-DetectAIve | 52.83 | 47.31 | 64.62 | 53.28 | 0.4733 | 0.4722 |
| T5-Sentinel | 55.56 | 49.54 | 66.67 | 55.34 | 0.4444 | 0.4444 | |
| SeqXGPT | 40.60 | 43.81 | 31.87 | 36.72 | 0.8021 | 0.7028 | |
| FAID | 62.78 | 70.73 | 71.77 | 69.46 | 0.4514 | 0.4486 | |
| Unseen generators | LLM-DetectAIve | 75.71 | 73.25 | 75.63 | 74.30 | 0.3714 | 0.2957 |
| T5-Sentinel | 85.95 | 85.77 | 84.59 | 85.16 | 0.3648 | 0.2419 | |
| SeqXGPT | 72.04 | 60.33 | 48.94 | 54.12 | 0.4590 | 0.3380 | |
| FAID | 93.31 | 92.40 | 94.44 | 93.25 | 0.1691 | 0.1167 | |
| Unseen domain & generators |
LLM-DetectAIve | 62.93 | 66.74 | 71.17 | 61.97 | 0.4479 | 0.3964 |
| T5-Sentinel | 57.07 | 49.82 | 66.61 | 55.45 | 0.4314 | 0.4300 | |
| SeqXGPT | 40.71 | 47.95 | 35.21 | 40.09 | 0.8753 | 0.7086 | |
| FAID | 66.55 | 74.44 | 73.57 | 72.58 | 0.3939 | 0.3167 |
FAID clearly outperforms all baselines on unseen generators, reaching 93.31% accuracy, and also provides the strongest results when both domains and generators are unseen. Generalizing to unseen domains remains challenging for all methods, but FAID still delivers the highest accuracy at 62.78%, demonstrating improved robustness over competing detectors.
Overall, the results indicate that FAID effectively captures generalizable stylistic signals tied to LLM families, enabling superior performance across both in-domain and out-of-domain scenarios without overfitting to surface-level artifacts.
BibTeX
@misc{ta-etal-2025-faid,
title = {{FAID}: {F}ine-Grained {AI}-Generated Text Detection Using Multi-Task Auxiliary and Multi-Level Contrastive Learning},
author = {Minh Ngoc Ta and Dong Cao Van and Duc-Anh Hoang and Minh Le-Anh and Truong Nguyen and My Anh Tran Nguyen and Yuxia Wang and Preslav Nakov and Sang Dinh},
year = {2025},
eprint = {2505.14271},
archivePrefix = {arXiv},
journal = {ArXiv preprint},
volume = {arXiv:2505.14271},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2505.14271},
}